
“Drift detection” sounds like one of those must-have features in modern infrastructure. It’s baked into tools, marketed heavily, and often treated as a best practice, but do we really need it? In most well-structured environments, drift shouldn’t be something you detect, it should be something you prevent. Drift Is a Symptom, Not the Problem TerraformContinue reading "The Role of Drift Detection in Modern Infrastructure"
Returning Complex Objects from Terraform External Data Sources

Terraform’s external data source is a useful escape hatch when you need to call out to a script to fetch data that isn’t available via a provider. However, it comes with a sharp edge that often catches people out: Terraform expects the result to be a flat map of string → string values. If yourContinue reading "Returning Complex Objects from Terraform External Data Sources"
Deploying Azure Purview with Terraform: Overcoming AzureRM Limitations

Microsoft shifted the Azure Purview to be Tenant aligned, but the AzureRM Provider hasn't made that move yet, so if you are deploying your Azure infrastructure using Terraform you need to do some alternative changes to get it to work, especially when you’re trying to deploy Purview securely using private networking. After a few painfulContinue reading "Deploying Azure Purview with Terraform: Overcoming AzureRM Limitations"
Secure MLOps Design for Databricks and Azure: A Practical Workspace‑Driven Architecture
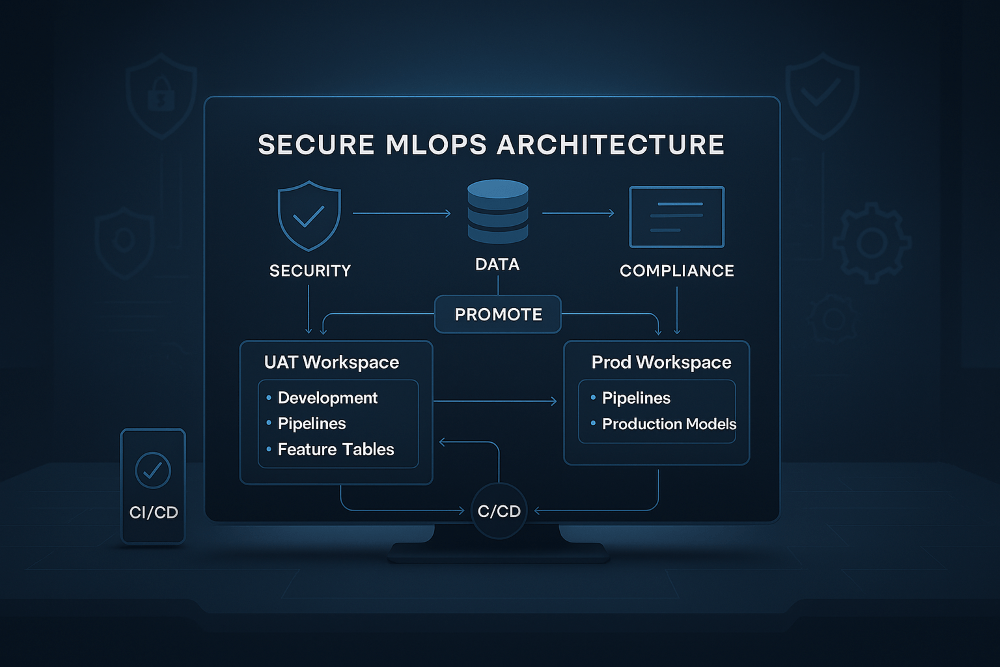
Most Databricks MLOps guidance assumes you can train and develop directly inside a production Unity Catalog. In many organisations, that’s simply not possible, whether for compliance, data‑security, tenancy boundary or governance reasons. So this post outlines a design concept I created that stays aligned with official Databricks and Azure MLOps guidance while enabling safe, isolated,Continue reading "Secure MLOps Design for Databricks and Azure: A Practical Workspace‑Driven Architecture"
Bringing AI-Powered Pull Request Reviews to Azure DevOps
AI‑assisted pull request (PR) reviews are quickly becoming standard practice in modern software delivery. GitHub users already benefit from Copilot being deeply embedded into their workflow, offering immediate feedback on code quality, readability, and potential issues at the moment of review. For teams using Azure DevOps, that experience simply doesn’t exist today. There is currentlyContinue reading "Bringing AI-Powered Pull Request Reviews to Azure DevOps"
Choosing the Right Azure DevOps Agent Hosting Strategy in Azure

In the world of continuous integration and continuous delivery (CI/CD), Azure DevOps agents are key resources. These agents are the compute resources that execute your pipeline whether it's compiling code, running tests, or deploying applications. Without them, your DevOps pipelines are just scripts waiting to be run. Azure DevOps offers two types of agents: Microsoft-hostedContinue reading "Choosing the Right Azure DevOps Agent Hosting Strategy in Azure"
How to Secure Your Terraform State File in Azure

Terraform has become the standard for managing cloud infrastructure, and with good reason. It provides consistent, repeatable deployments and integrates with almost every cloud provider. But there’s one piece that’s often overlooked until it causes problems: the Terraform state file. Your terraform.tfstate file is more than just metadata — it’s the single source of truthContinue reading "How to Secure Your Terraform State File in Azure"
Implementing Test-Driven Development with Terraform

Test-driven development (TDD) isn’t just for application code anymore; Terraform has a native testing framework that lets you plan/apply infrastructure from tests, make assertions in HCL, and even run post-deployment checks that behave like smoke tests. In this post I’ll show you how to do TDD with Terraform (TTD), when to use plan vs applyContinue reading "Implementing Test-Driven Development with Terraform"
